
検証に使った動画
自分の動画です()
自分はk,gなどの発音が苦手です。
喋るのが少し早いと言われることもあり、さらに文法も結構ぐちゃったりします。
精度差が出やすいような気がしたので、自分の動画を採用しました。
結果
検証動画をまるまる書き起こしさせたのですが、流石に長いので最初の40秒の書き起こし結果をそのまま載せます。
実行時間に関しては、検証動画全体(3分間)の書き起こし処理にかかった時間です。
精度の違い
・baseモデル結果
大学生が買う武器ものとか行っても、結局ね、その人個人によるんですけれども、今回はできる的不園的にね、人々の大学生に役に立つやろうグッズ3線を私選びましたので、紹介させていただきます。第3位、こちらですね、なんていうんでしょうか。パソコンを上げる台、パソコンスタンドみたいなの。これで地味だけど、めちゃくちゃ便利で、大学生でみなさんのノートバスコン買うと思うんですけど、ノートバスコンをここに置いてですね、そのノートバスコンパチパチしてる姿を横から見たことありますか?僕はないんですけど、多分めちゃくちゃ首がすごくてなってますよね。実際、僕はあの、ぎっくり腐しなら、あの、ぎっくりせなかったっていうのになって、あの、本当にそういうのあって、それで、でもその位置にこの多分、ここにノートバスコンを置いて首を出してね、やつだっていうのが多分、気にしてるんですけれども、
・largeモデル結果
大学生が買うべきものとか言っても結局その人個人によるんですけれども今回はできるだけ普遍的に任意の大学生に役に立つであろうグッズ3選を私選びましたので紹介させていただきます第3位こちらですねこれ何て言うんでしょうかパソコンを上げる台パソコンスタンドみたいなやつあのねこれ地味だけどめちゃくちゃ便利で大学生って皆さんノートパソコン買うと思うんですけどノートパソコンをここに置いてですねそのノートパソコンパチパチしてる姿を横から見たことありますか僕はないんですけど多分めちゃくちゃ首がすごいことになってますよ実際僕はぎっくり腰ならぬぎっくり背中っていうのになって本当にそういうのあってそれでその一因に多分ここにノートパソコンを置いて首を出してねやってたっていうのが多分起因してるんですけれども
精度がまるで違います。
baseモデルでは、間違って書き起こされた単語が多いです。3分全体の書き起こしも見ましたが、何言ってるかよく分からんものとなりました。
しかし、largeモデルはパッと見完璧に書き起こし出来ているように感じます。すごいですね。
目立つ特徴としてlargeモデルには句読点が入っていないということがあげられますが、これは何かを自分がミスった?
さて、こうなると問題は実行時間ですが……
実行時間の違い
検証動画(3分間)の書き起こし処理にかかった時間。実行環境はGoogle Colabです。
baseモデル:2分29秒
largeモデル:27分8秒
largeモデルはめっちゃ時間かかりました。
baseモデルで事足りるように、まともな日本語を喋りましょう(自戒)。

おまけ:WhisperでYouTubeの動画を文字起こししてみよう(コピペでOK)
動画DLして書き起こししてるだけの処理なんですけど、プログラミング全く分からんって人もコピペで遊べるように、少し説明します。
まず、下のコードをコピーしてGoogle Colabにペーストします。
!pip install pytube
!pip install git+https://github.com/openai/whisper.git -q
import whisper
from pytube import YouTube
import os
#音声ファイル入れるフォルダ作成
os.makedirs("output", exist_ok = True)
#DLする動画のURLをinputで入力
yt = YouTube(str(input("動画URLを入力してください\n")))
#音声抽出
audio = yt.streams.filter(only_audio=True).first()
#音声ファイルDL
out_file = audio.download(output_path="./output")
# DL完了
print(f"『{yt.title}』がDLされました\n")
#音声書き出し & テキストファイルとして保存
model = whisper.load_model("base")
text = model.transcribe(out_file,language="ja")
with open("video.txt","w") as f:
f.write(text["text"])↓こんな感じ。
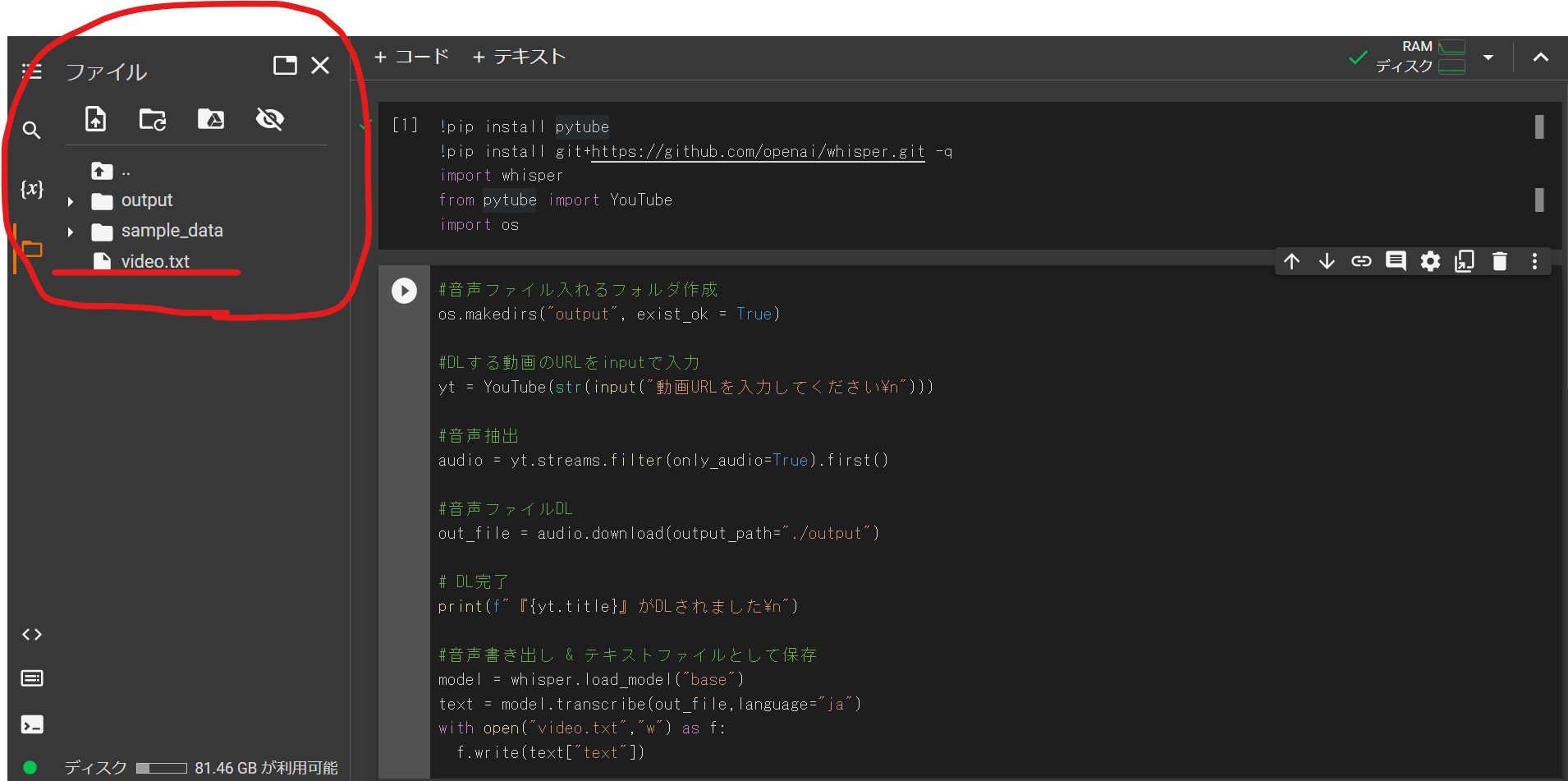
上から順に実行します。1つ目のセル(1行目からimport osまで)は一回実行したらその後実行しなくて良いです。色々試したい時は2つ目のセルだけいじります。
2つ目のセルを実行すると、入力欄がでてくるので、書き起こししたい動画のURLを貼り付けてエンターを押してください。
しばらく待つと、上画像赤丸で囲った部分にoutputという名前のフォルダと、video.txtが現れると思います。
outputフォルダの中にDLした動画の音声ファイルが入り、video.txtは書き起こし結果です。
model = whisper.load_model("base")のbaseの部分を変えると精度が変わると思います。base, largeの他は以下の通り(公式から引用)。
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
書き起こし結果をChatGPT APIに投げて「これブログ用に書き直して~」とかお願いしたらうまいことやってくれそう。色々遊べそうですね。
以上。


コメント